


當機器學習撞上高牆:為什麼電腦分不出長頸鹿和貓咪? -《了解人工智慧的第一本書》

編按:人工智慧的發展已漸漸成熟,不再只是電影中的虛構情節,本文選自該書《了解人工智慧的第一本書:機器人和人工智慧能否取代人類?》的第四章(「機器學習」悄悄地在擴大地盤:第三次人工智慧熱潮),解釋了機器學習的原理與應用,如何從獲取特徵量,來讓機器學習更聰明?
機器學習時的難題
透過機器學習,電腦可以自行學會「如何分類」「如何畫邊界線」,以及判斷、辨識與預測未知的事物。這樣的技術,目前在網路與大數據的領域中受到廣泛的運用。但機器學習也有弱點,在於「特徵工程」(feature engineering)的部分,也就是特徵量(與生俱來的特性)的設計,在此稱為「特徵量設計」。
所謂的特徵量,是機器學習在輸入時使用的變數,它的數值可定量呈現目標的特徵。機器學習隨著所挑選特徵量的不同,而讓預測精確度產生很大的變化。
例如,在手寫文字辨識方面,必須調整圖像的中心與大小、設計特徵量。先前為了讓說明單純一些所以沒有觸及, 精確度的提升並非只靠把圖像切分到以像素單位就能辦到。
挑選何種特徵量,對於預測的精確度會帶來決定性的影響。不妨想想「預測某人年收入」的狀況,就會很好懂。這個人住在哪?他是男是女?利用諸如此類的特徵量預測年收入,就像是透過神經網路或其他的機器學習方法學習一樣。這時,要以什麼為特徵量?換句話說,要讓電腦讀入什麼樣的變數,才能對提升預測精確度帶來最大貢獻?這應該很容易想像吧。
如【圖表18】所示,「性別」或「居住地區」感覺和年收入有關係,但「身高」就教人打個問號了,「喜歡的顏色」應該關係不那麼大。相較之下,反倒是「年齡」「職業」「產業別」「擁有的證照」等變數,更可能影響到年收入。假設真的在資料庫中加入「生日」這個欄目,光是這樣仍稱不上是良好的特徵量。改為登錄「生日與目前日期之間的差距」,也就是「年齡」這個數值,似乎對於預測年收入一事才會比較有幫助。
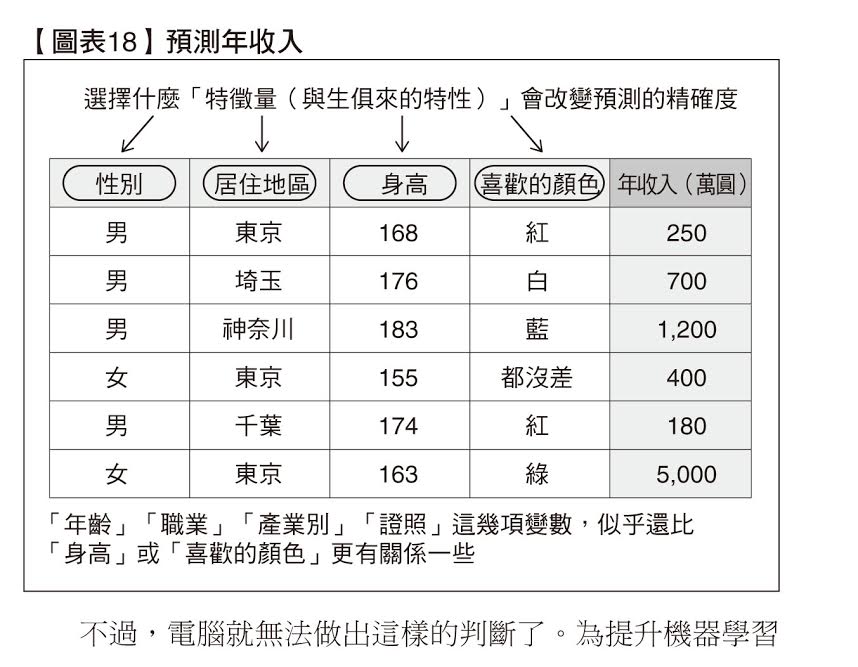
不過,電腦就無法做出這樣的判斷了。為提升機器學習的精確度,牽涉到「要放什麼特徵量」,而這只能靠人類動腦思考 這就是機器學習的最大關卡「特徵量設計」。
對此,我回想起學生時代的往事。
一九九八年左右,我在上以自然語言處理知名的黑橋禎夫(Sadao KUROHASHI)老師(現任京都大學教授)的課。他是一位在日本對這方面的研究帶來莫大影響的研究者。不光自然語言處理,他還談了很多資料庫與程式設計的事情,課程內容很有趣。但在完成對於機器學習的漫長說明後,黑橋老師卻淡淡地說了一句,
「唔,方法很多,不一而足,但到頭來,最辛苦的其實還是要找出夠好的特徵量,這就只能由人類來做啦」。
他這番話讓我深感震驚,彷彿當頭棒喝。因為,他乾脆地把我一直在想的事情講出來了。這是我頭一次在自己以外的別人嘴裡聽到「特徵量的安排對機器學習來說屬於本質性問題」這件事。之後,大家才開始普遍體認到特徵量設計這個問題。
人類很擅於掌握特徵量。在看到同一個對象時,都會自然而然察覺到對方隱藏於內在的特徵,藉以更輕鬆地理解對方。或許各位曾經聽某一行的前輩,以簡單得驚人的方式把事情講得很清楚。只要能掌握住特徵,看起來複雜的事情, 還是可以整理得很簡單、很好懂。
人類在視覺資訊上也在做同樣的事。例如,對人類來說,要區分某個動物是象、是長頸鹿,還是斑馬或貓,是輕而易舉之事;但對電腦來說,要它找出必要的特徵,以根據圖片資訊分辨這些動物,就十分困難了。就算要讓電腦做機器學習,要是無法適切地找出其特徵,學習這件事還是不會順利。
為何至今未能實現人工智慧?
好了,暫且先跳開機器學習的話題,包括本章到此為止介紹過的內容在內,一起重新來思考一下吧。
在第三章裡,我們觸及了一個問題:只要輸入「知識」,固然可以讓人工智慧變聰明,但「知識」卻是再怎麼寫也寫之不盡的。另外還有「框架問題」:針對不同性質的任務,難以事前決定,機器人該使用什麼樣的知識。還有「符號接地問題」,對電腦來說,它無法理解斑馬就是「有斑紋的馬」這件事。
相較之下,在本章提及的機器學習,則是得由人類來決定,要以什麼作為特徵量才行。只要人類能設計適切的特徵量,機器學習就能順利運作,否則運作狀況將難如預期。
這些問題,到頭來都指向同一件事:一直以來,我們之所以無法實現人工智慧,是因為關於「應該在這個世界裡關注何種特徵、取得資訊才好?」這件事,還是非得借重人類的手不可。
也就是說,只要電腦能夠在給予的資料當中,找出應該關注的特徵,獲得用於表達該特徵的程度高低之「特徵量」, 就能解決在機器學習中存在的「特徵量設計」的問題。
符號接地問題也一樣,只要電腦能自己找出特徵,以及用於表達特徵的概念(像是「有斑紋的馬」),再來就只需要給個符號名稱(斑馬),由人類把雙方連結在一起,電腦就能理解符號的意義、並予運用了(就像當媽媽的把物品的名稱教給孩子一樣)。
框架問題也是,只要能根據資料、抽取出現象的特徵, 再運用使用了該特徵的概念來表達知識,應該不致於老是碰到例外之事。此外,也不致於「為了挑出必要的知識,而陷入無限的思考」。
過去,語言哲學家費爾迪.德.索緒爾(Ferdinand de Saussure,一八五七∼一九一三)認為,所謂的符號,就是概念(signifié;符號義)與名稱(signifiant;符號具)表裡一致而連結起來的東西。符號義也可以說是符號的內容,符號具也可以說是符號的表達。如【圖表19】所示,符號具處的「貓」這個字,其實隨便取什麼都可以,但是等到連結起來之後,大家就知道要用「貓」這個名稱(符號具)來表達貓的概念(符號義)了,而且也會這樣使用。
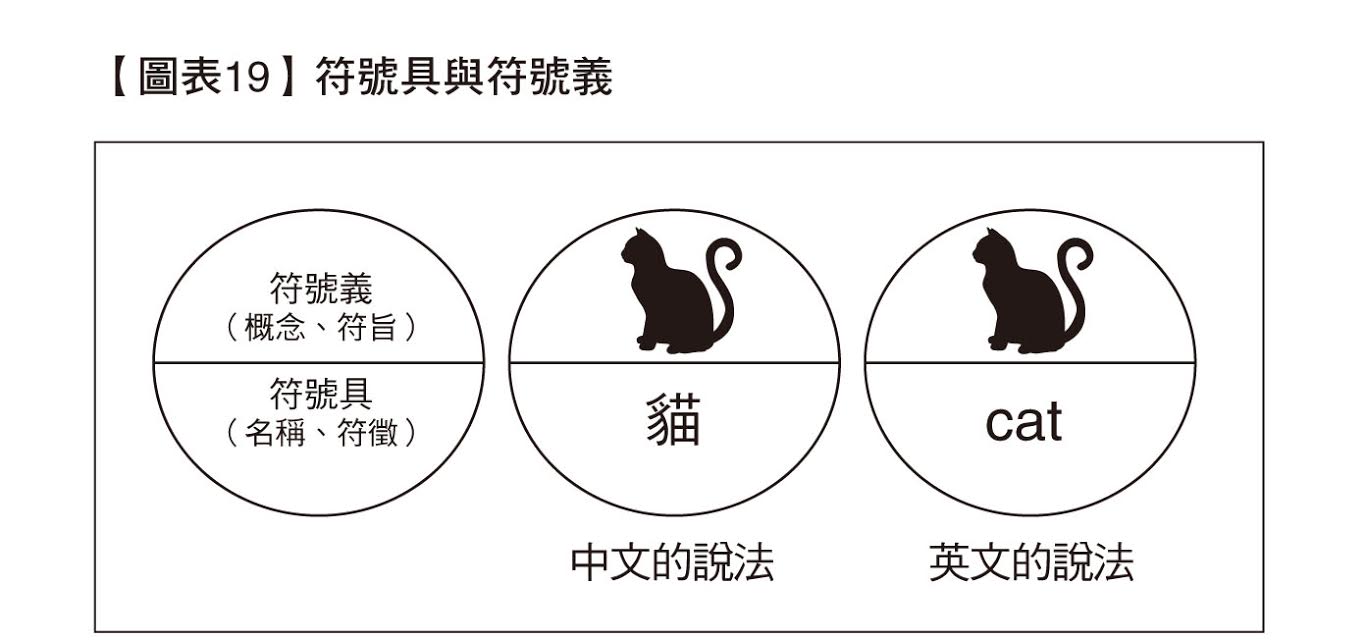
只要在電腦從資料當中取出特徵量、用它來獲得「概念(符號義;符旨)」後,再賦與「名稱(符號具;符徵)」,那麼根本不會發生符號接地問題。而且,也不會只使用「特定狀況下的知識」,而可以因應狀況、因應目的, 自行創造適切的符號,再自行獲得與活用使用了該符號的知識。一直以來,人工智慧之所以面臨各種問題,是因為它無法自行得到概念(符號義)使然。
現在,已經漸漸出現一些方法,可以讓電腦在收到的資料當中,生成重要的「特徵量」。電腦漸漸有了獲得符號義的眉目了。下一章就要談談人工智慧五十年來的大突破,也就是「深度學習」。
- 本文出自城邦出版集團經濟新潮社出版《了解人工智慧的第一本書:機器人和人工智慧能否取代人類?》

- 書名:《了解人工智慧的第一本書:機器人和人工智慧能否取代人類?》
- 出版社:城邦出版集團經濟新潮社
- 作者: 松尾豐
關於作者
|
|
泛科選書(PanBooks)PanX 泛科技新聞網從科技議題著手,企圖把未來更清楚地描繪出來。從能源議題、金融科技、生物科技,到物聯網、大數據、工業4.0、自造者,都是我們專注的內容。若希望有任何書籍合作歡迎向我們聯絡:contact [at] panx.asia |








留言討論