


利用機器學習判定,紅樓夢全書是否為曹雪芹所寫

作者/黎晨
前幾天朋友給我發了一篇文章,講的是用機器學習的方式來判定紅樓夢後 40 回到底是不是曹雪芹寫的。我這段時間也在自學 Andrew Ng 的機器學習課程,還差 4 週就能完成課程了。計算機是一個很強調 learning by doing 的學科,於是我也來「學以致用」,用剛學到的 SVM 演算法來分析下曹雪芹到底有沒有寫紅樓夢後面的 40 回。
作為一個從沒看過紅樓夢的人,我的大致思路是這樣的:
1. 受到漫畫「獵人」裡蟻王破解會長無敵招數的啟發,每個人的寫作都有些小習慣,雖然文章前後說的內容會有差別,但是這些用詞的小習慣不容易改變。
2. 用開源的分詞工具把全書分詞(python 的 jieba 分詞),然後統計用詞頻率,把出現次數超過 100 次的詞語找出來,人工去掉一些可能因為文章內容造成前後出現不一致的人名、 地名。
3. 然後每一章按照 2 中的用詞頻率表,看這一章中出現這些詞語的次數。
4. 前 80 回、後 40 回各選 15 回作為機器學習的數據,讓機器學習這些章節的用詞特點,然後推算其他章節的用詞特點是屬於前 80 回呢?還是後 40 回呢?
5. 如果機器根據這些用詞特徵推算的是否屬於後 40 回的結果跟實際的結果吻合,那麼就說明後 40 回的寫作風格跟前 80 回有很大不同,很可能是兩個人寫的。
好了,下面我盡量少涉及數學跟編程的知識,來一步步解讀機器學習是怎麼完成這個問題 的。
生成全書的用詞頻率表:
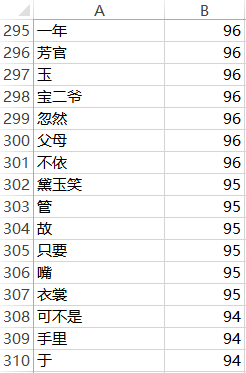
我截取了其中一段的用詞頻率表,像寶二爺、黛玉笑這種涉及人物的詞語,可能前面戲份多、 後面戲份少,所以就不選它們作為用詞習慣的特徵,而像忽然、故、只要、可不是這種承 接性質的碎詞,就不太容易會受情節的影響,所以適合選出來作為用詞習慣的特徵。 最終,我按照出現從多到少排序,選擇了 278 個詞作為機器學習的用詞習慣。
將 120 回的詞頻進行統計
接下來我把每一回出現這 278 個詞的用詞頻率統計出來,得到我們給機器學習的樣本。這個樣本的樣子大概是這樣的:
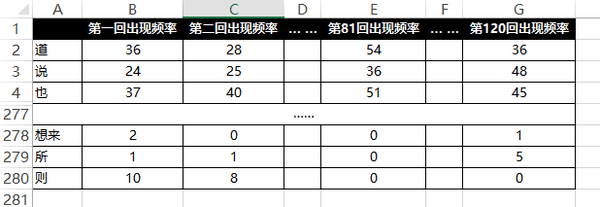
比如以 B 行 2 列舉例,說明在第一回裡面「道」這個動詞,出現了 36 次。 通常我們在進行複雜的事情前,喜歡先簡化問題,或者給自己一些直觀的圖表,以便了解 問題。機器學習也是一樣的。
我嘗試著在圖上把前 80 回和後 40 回習慣用詞出現的用詞頻率畫出來。以第一回為例,x1 坐標代 表「道」出現多少次,x2 坐標代表「說」出現多少次,x3 坐標代表「也」出現多少次 ……x280 坐標代表「則」出現多少次。
什麼?超過三維了,那人類的大腦可是沒辦法理解的啊。 沒關係,當我們用燈光照射一個立體的圖時,平面會有它的影子。這個影子雖然沒有立體圖的信息這麼豐富,不過我們看影子還是可以猜出來大致的樣子。對於高緯度的問題,我們也可以用投影的方式來降低緯度。 雖然信息損失了不少,不過能給我們一個直觀的感受。
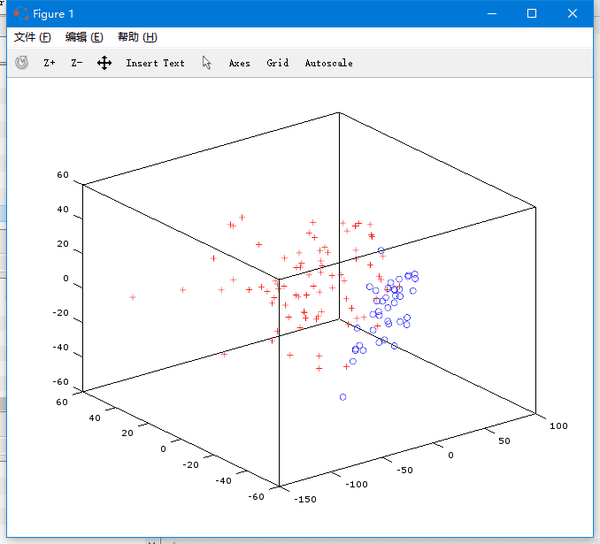
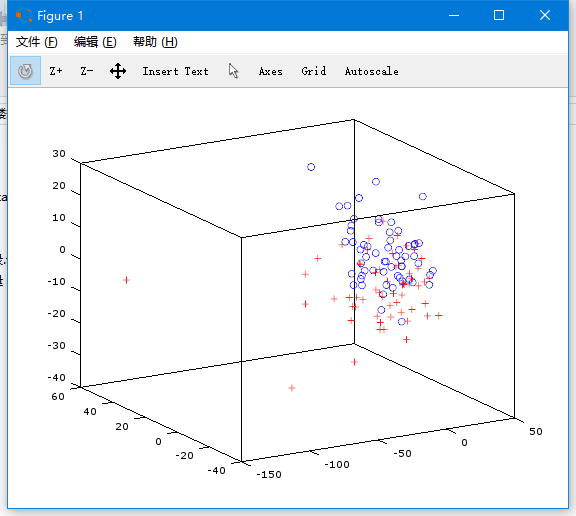
這個是 120 個章節的用詞習慣從 278 緯降到 3 維以後的圖,紅色+的點是前 80 回,藍色 o 的點 是後 40 回。 從這個圖可以直觀地看到,確實在用詞習慣上有明顯的區別。就算我們沒有機器學習工具的幫忙,也可以大膽猜測後 40 回是出自於另外一個人了。 下面我們用機器學習來看精確一點的判斷。
機器學習
通過課程我大致了解了 SVM 演算法的原理和簡化版問題的算法實現,不過對於複雜問題我還是沒這個編碼能力的。於是用 python 的 scikit 庫來幫助我來完成這個預測。 算法的步驟很簡單,前 80 回、後 40 回各選 15 個來餵給機器學習它們的特點,然後把剩下的章節輸入給機器,問它們屬於前 80 回還是後 40 回。
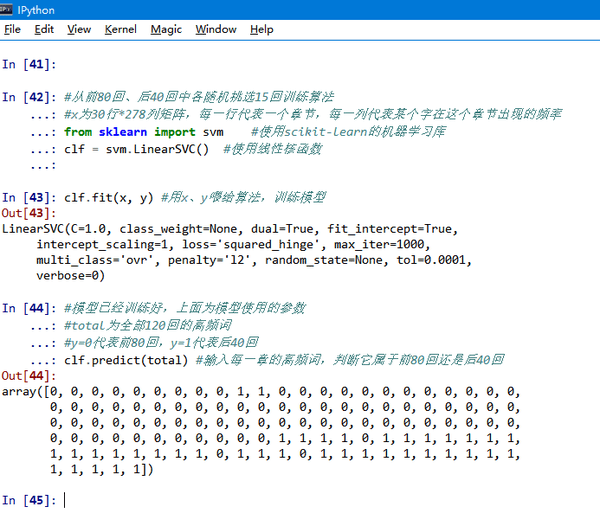
看 out[44] 的結果,代表了機器預測這 120 回的用詞習慣到底屬不屬於後 40 回(0 為不屬於 ,1 為屬於)。
如果你看不懂上面的代碼,沒關係。我告訴你結果好了。 機器在學習以後告訴我,如果我把隨便一章的用詞習慣告訴它、但不告訴它到底是前 80 回 還是後 40 回,那麼機器有 95% 的把握能猜出它是不是後 40 回。 至此,我們可以很有信心地判斷它們的寫作風格不同。 那麼,問題來了,會不會因為是情節的需要所以導致寫作風格不同了呢?
情節不同會造成用詞習慣多大的差別?
好吧,那我再來做一個旁證。我把另外一部四大名著「三國演義」拿來分析,看看上部跟下部的用詞習慣會不會有比較明顯的差別。
這個是三國演義的用詞習慣縮到三維以後的圖,紅色 + 代表前 60 部的用詞習慣,藍色 o 代表後 60 部的用詞習慣。 你可能會說,雖然中間交叉的地方比較多,但是還是可以看出來是有區分的。 可如果你比對一下跟紅樓夢的圖,你就會發現紅樓夢的差別會明顯得多。
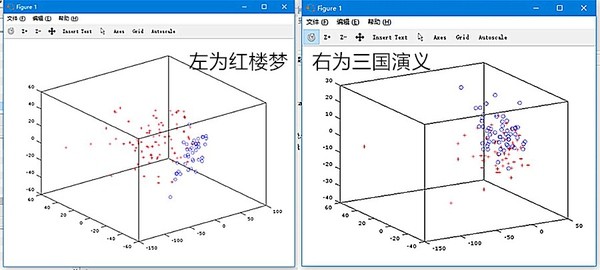
最後,用機器學習的方式來說,如果我把三國演義隨便一章的用詞習慣告訴它、但不告訴它到底是前 60 回還是後 60 回,那麼機器有 7 成的把握猜對,這個準確度已經遠遠低於紅樓夢的 95% 的預測水平。 所以,我們用「三國演義」這個旁證來分析,即便是因為情節需要導致的用詞習慣差別也不應該這麼大。 所以,我們就更有信心說曹老先生沒有寫後 40 回了。
更多的機器學習有趣的玩法,我會在學習的過程中慢慢嘗試的,以上。
(本文轉載自:知乎:用机器学习判定红楼梦后40回是否曹雪芹所写)
圖片來源:紅樓夢百科關於作者
|
|
PanX 泛科技PanX 泛科技從科技議題著手,企圖把未來更清楚地描繪出來。從能源議題、金融科技、生物科技,到物聯網、大數據、工業4.0、自造者,都是我們專注的內容。本帳號也會發布來自其他單位提供的新聞稿。 |








留言討論