


3 分鐘搞懂深度學習到底在深什麼

深度學習其實跟 VR 很像,他們都不是全新的概念,卻在這幾年因為硬體進步而死灰復燃。深度學習是機器學習的一種方式,也可以說是目前人工智慧的主流,今年擊敗世界棋王的 Google AlphaGo,2011 年奪得益智問答比賽大獎的 IBM Watson 都是最佳代言。
要設計出比天才還厲害的電腦,一定是比天才還聰明的人囉?答案是:不,建構一套深度學習的網路,其實沒有想像中困難,只要看完這篇文章,就能夠有基本的了解,再搭配網路資源自學一下,甚至就可以開始建立自己的深度學習網路。
如果你想要深度學習「深度學習」,又能快速搞懂它到底在深什麼東西,看這篇文章就對了,那我們開始囉!(ㄟ跑錯棚了吧)
(本文內容來自資料科學年會 2016 議程,未加註來源之圖片取自台灣大學電機系助理教授李宏毅之簡報)
什麼是深度學習?
深度學習其實很簡單,就跟把大象放進冰箱一樣,只需三個步驟:「打開冰箱、放進大象、關上冰箱門。」專攻語音辨識領域深度學習的台大電機系教授李宏毅說,「深度學習也只要三個步驟:建構網路、設定目標、開始學習,說穿了就是這麼簡單。」

「簡單說,深度學習就是一個函數集,如此而已。」李宏毅說,類神經網路就是一堆函數的集合,我們丟進去一堆數值,整個網路就輸出一堆數值,從這裡面找出一個最好的結果,也就是機器運算出來的最佳解,機器可以依此決定要在棋盤上哪一點下手,人類也可以按照這個建議作決策。
這段敘述也許太過抽象,我們可以先具體的說明一下函數。
假設有一個函數叫總統府,這個函數的內容是 x = 無能,那麼無論我們輸入的是小馬、小英、地產大亨或前總統的妻子,最後的結果都 = 無能。
當然現實世界不會這麼簡單,總統府裡面高深莫測,就像深度學習的類神經網路一樣,我們可以在這個函數裡加進各種變數,來模擬兩黨政治、全球暖化、恐怖攻擊等考量,經過一層又一層的運算之後,最後從總統府輸出的,就是這個函數集建議的最佳決策。
但現實世界中,這個函數集更複雜,而且要等好幾年,才能看到結果。在程式設計裡,我們不但可以很快看到結果,還可以告訴機器,這個結果 no good,請調整函數內容,給我其他結果。這個過程,就是所謂的「學習」,經過大量的訓練過程,最終機器就能找到一個最佳函數,得出最佳解。
以 AlphaGo 為例,團隊設定好神經網路架構後,便將大量的棋譜資料輸入,讓 AlphaGo 學習下圍棋的方法,最後它就能判斷棋盤上的各種狀況,並根據對手的落子做出回應。
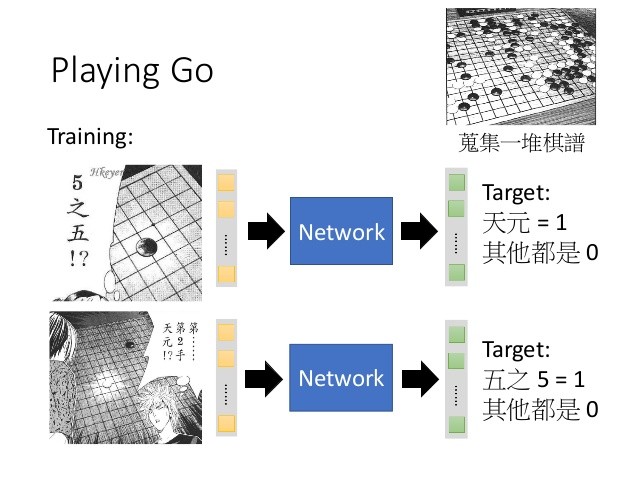
「AlphaGo 很厲害,但是它只能下棋,它的架構就是為了圍棋而存在的,要拿去開車就必須要重新設計」李宏毅表示,深度學習並不是萬能的人工智慧,它其實只能針對特定的需求來設計,現在的各種酷炫應用都還在原始階段,還有很多需要人類去定義、設計,未來當機器可以自己定義架構時,就更加值得期待。
聽起來一點都不簡單啊!
其實,深度學習的概念早在 90 年代就存在,那時是以類神經網路的概念發表,但是當時的電腦運算能力不足,因此效率不彰,導致後來只要提到神經網路,就沒人關注,直到近幾年換上深度學習的名字才捲土重來。
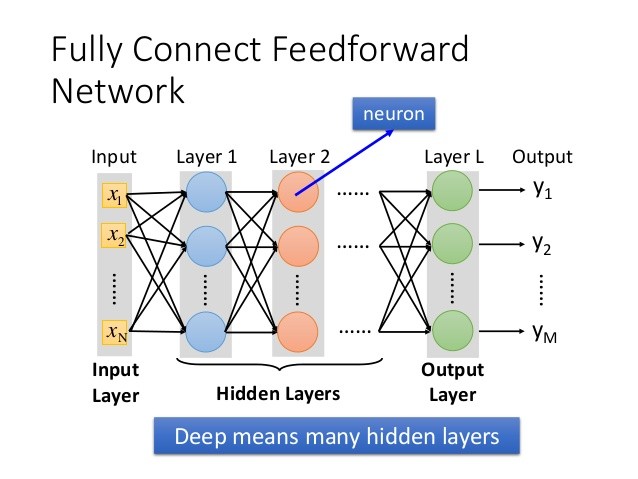
深度學習的網路架構層層疊疊,說這個東西很簡單的肯定是瘋子,但事實上它又真的很簡單,因為這是「機器學習」啊。
一般來說,我們看到十幾層的網路,就會想到每一層要怎麼設定各自的權重(weight)跟變數(parameter),然後還要互相串連,並且運算在極龐大的資料庫上。假設這個網路每一層有 1000 個神經單元(neuron),那每一層中間就有 100 萬個權重,疊加越多層越可怕,這怎麼會簡單?
如果所有的細節都要人類去設定,那就不叫做「機器學習」了,這個系統厲害的地方就在於,在神經網路裡的千百萬個數值細節,都是機器自己學出來的,人類要做的事情就是給他「規則」跟海量的學習資料,告訴機器什麼答案是對的,中間的過程完全不用操心。
舉例來說,Google 就嘗試讓機器手臂自己學習如何抓握不規則物品,與其透過人類不斷去修正每個動作的精準度,還不如讓機器自己學習,最後讓失敗率下降了 16%。
在目前主要的深度學習架構裡,人類要擔心的重點只有一個:「Gradient Descent」,中文勉強譯做梯度下降法。我們可以把深度學習想像成有一百萬個學生同時在寫答案,他們每個人都有不同的思考方式,最後每個人都交出一個不同的答案(一個數字)。將所有的答案跟標準答案相減之後(技術上稱為 loss),畫成一條折線圖(或是複雜一點的 3D 圖),離標準答案最接近的那個答案,就會在這張圖的最低點,深度學習的目標就是要找到這個最低點。
最低點代表什麼呢?代表寫出這個答案的學生,擁有最接近正確答案的思考方式,接下來我們讓其他學生向這位學生學習,並繼續測試,是否都能回答正確。理論上,隨著測試次數越多,正確率就會越高,表示這個機器已經通過測試,可以投入實戰分析了。
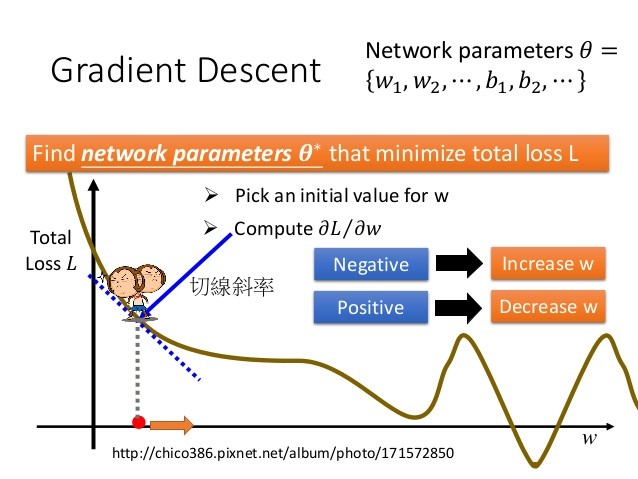
看到這裡,如果你想跟朋友炫耀一下什麼是「深度學習」,就跟他說「很簡單啊,就是在找 loss 最小的點嘛,Gradient Descent,懂?」
深度學習越深越好嗎?
深度學習之所以厲害就在於它堆疊了很多層,因此很多人會好奇,神經網路越多層就越好嗎?這個問題的答案跟「頭大的人就比較聰明嗎」差不多:不一定。
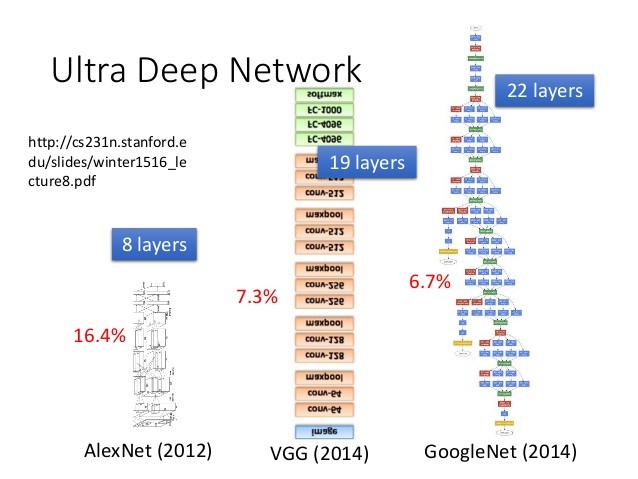
雖然從這幾年的一些機器學習競賽結果來看,似乎越多層就能得到更低的錯誤率,去年 Residual Network 堆到 152 層,錯誤率也低到 3.57%(ImageNet 資料庫的測試結果)。但是堆疊上百層的神經網路,常常會導致「Vanishing Gradient」,也就是因為每一層運算讓數值不斷收斂,導致最後的 output 越來越小,跟正確答案相減之後也就看不到顯著的最小值,看起來到處都是最小值。
那你可能又會問,像前面說的,把所有的答案列出來跟標準答案比對,怎麼會找不到最小值呢?事實上,我們面對的可能不只一百萬個答案,很可能是千萬或上億個答案,實作上幾乎不可能列出所有的答案去「窮舉」它,而是用隨機抽選的方式,在線上找一個點,然後比對它旁邊的數值,看看是否更低,慢慢去貼近最低點,像在爬樓梯一樣漸漸往下所以才稱為 gradient。
這會遇到一種狀況,當系統以為找到了最低點,但其實越過山丘,還會發現更低點;或者開局就落在高原上,附近超平坦的,就覺得應該是最低點了,其實遠方還有人在谷底等候。
神經網路疊加的越多層,這個問題就會越明顯,因此需要設計不同的架構,跟特殊的運算過程,才能避免找不到最低點。有時候反而 layer 少一點,正確率還更高。
「目前我們嘗試的語音辨識模型,大概疊 8 層,是一個 C/P 值滿高的選擇。」李宏毅說,深度學習目前其實還在神農嚐百草的階段,甚至是寒武紀大爆發的時代,雖然很精彩,但是其實水準還很低階。也許不久後,就有人找出比 Gradient Descent 更有效的方法,那現在所學的很多幫忙找出最低點的技術就沒用了,但這也代表我們離高階人工智慧又更近一步。
圖像辨識、語音分析和種種可能
在學習深度學習的時候,我腦中一直浮現古老的豐年果糖廣告,爸爸驕傲的說「爸爸頭腦比電腦好啊」的畫面。從理論來看,人腦確實很強大,強大到機器也要模仿人腦來變得更聰明。
「人類的五感隨著演化過程互有消長,我們的嗅覺退化得很快,視覺則要處理最龐大的資料量。」專研影像辨識、智慧監控的 Umbo CV 技術長張秉霖指出,人腦處理一張圖像的資料量可能高達一百萬個位元,如果我們要用機器進行影像辨識,就一定要參考人腦的運作方式。
在深度學習中有很多方式去辨識圖像,其實作法跟人腦很像,第一層先處理基本的線條,然後再慢慢組合成一些形狀,最後就能判讀出圖形的意義,就像 2012 年的 Google Brain 就能夠從龐大的圖形資料中,分辨出貓臉跟人臉的不同。
「但是俗話說得好,一張圖勝過千言萬語,不同人對同一張圖片可能有不同的解讀,這是因為每個人對這張圖的背景知識認知不同。」張秉霖說,要讓機器圖像辨識再更上一層樓, 就要讓機器看懂圖像背後的脈絡,而要讓機器看懂脈絡,就需要讓它吸收大量知識,最好的辦法就是讓機器學會人類的語言,就可以學習到更多背景知識。
語音辨識面臨的問題則恰恰相反,之前的語音分析是將語音轉成文字,然後用文字進行語意分析,進而推理出這段語音的意思,這樣的作法無法判斷聲音情感,常常會誤判;新的作法則是將整段語音,丟到資料庫裡進行比對,找出最相近的聲紋,來理解這段話的意思。
透過深度學習,機器正在變得越來越聰明,人工智慧的運用也更加廣泛。目前已經有一些案例,像是美國的梅西百貨(Macy’s)、Hilton McLean 飯店還有喬治亞理工學院,也嘗試運用 IBM Watson 來擔任服務員、櫃台接待與課堂助教,透過回答一些簡單的問題,來減輕人類的負擔,人類就能專心處理那些棘手的難題。

不難想像,深度學習在未來會運用在更多領域,甚至還有人嘗試用 Watson 來抓神奇寶貝。不過,深度學習的原理與實作的門檻並不太高,真正的難處不在深度學習本身,而是在於如何將人類要解決的問題用數字來表達,並設計成機器可以學習的架構,如何用數字來表示貓臉?用數字來描述圍棋?這些都需要人類去定義,因此深度學習要進一步發展,最需要的其實是人才,剩下的,就是機器的事了。
封面圖片來源:extremetech.com









留言討論